CS186 Note
SQL真的这么难吗?
SQL
SELECT后加DISTINCT可以将重复的tuple去掉。1
2SELECT DISTINCT <columns>
FROM <tbl>;
NULL value
- 任何以
NULL值作为操作数的算数运算操作结果都为NULL,所以通常需要IS NULL或IS NOT NULL来提前判断。 NULLis falsey.
Aggregate funtion
- SUM, AVG, MAX, MIN, COUNT。
- 输入是一个列,输出是一个值。
- 每个aggregate都忽略掉
NULL, 除了COUNT(*)之外。注意COUNT<column>返回具体列非空值的数量。 - 注意分组后COUNT(*)计算的是当前组的行数。
Groups of Data
- GROUP BY
- 将当前列中属性值相同的行放入一个组中, 该组中的所有行要合并为一行。
1
2
3
4
5SELECT <columns>
FROM <tbl>
WHERE <predicate> −− Filter out rows (before grouping) .
GROUP BY <columns>
HAVING <predicate>; −− Filter out groups (after grouping) . - WHERE用于过滤行,而HAVING用来过滤组。
有问题的查询语句
- 投影的属性
AVG(num dogs)是只有一个值,但是age属性中有很多值。因此形成的表中必须有同样数量的行,error。1
2SELECT age, AVG(num_dogs)
FROM Person; - 将age分为一个组之后,无法合并为一行(因为age在当前组中含单个数字,但num_dogs含多个数字),error。
1
2
3SELECT age, num_dogs
FROM Person
GROUP BY age;
Order By
- 默认是升序排列的,要想降序排列需要具体列名(属性名)后加关键字DESC。下面语句列num_dogs按升序排列,但name按降序排列。我们先对num_dogs排序再对num_dogs中相同的行进行name降序排序。
1
2
3SELECT name, num_dogs
FROM Person
ORDER BY num_dogs ,name DESC;
LIMIT
- 限定返回的行数
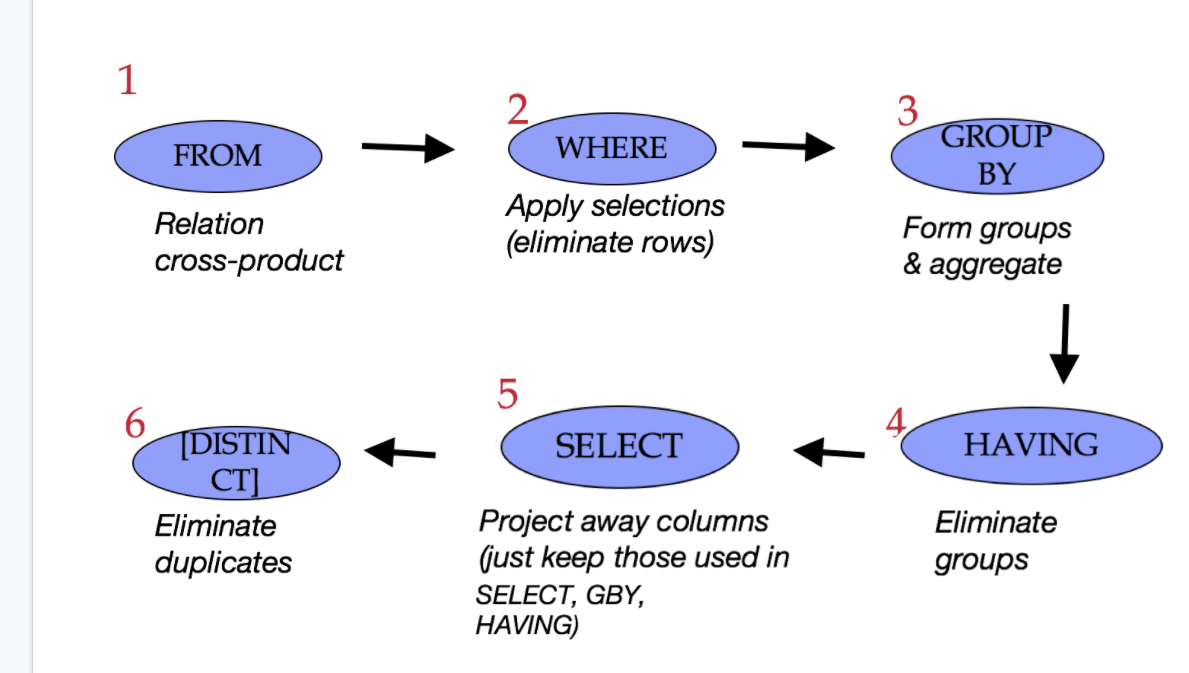
语句编写顺序
1 | SELECT <columns> |
Join
- cross join(笛卡尔积), filter在笛卡尔积过后的表中寻找对应的行。
1
2
3SELECT *
FROM table1, table2
WHERE <predicate> - inner join,和上述语句输出是一样的结果。
1
2
3
4
5
6
7
8
9
10
11SELECT *
FROM table1 INNER JOIN table2
ON <predicate>
- outer join, 除了加上共有的属性值行...
- left outer join, 加上左侧表中特有的属性值行,当前右侧表中对应的不存在的属性用NULL代替。
- right outer join, 加上右侧表中特有的属性值行。
- full outer join, 加上两侧表中特有的属性值行。
- natural join, **隐式地**将属性值一致的列inner join, 比如在当前例子中,将会自动包含join condition: courses.num = enrollment.num。
``` sql
SELECT ∗
FROM courses NATURAL JOIN enrollment; - ON后跟的是连接的predicate。
Name conflict
- 通过
列名.属性来避免命名冲突。1
2
3SELECT ∗
FROM courses INNER JOIN enrollment
ON courses.num = enrollment.num; - 通过AS来指定别名。
1
2
3SELECT *
FROM courses AS a INNER JOIN enrollment AS b
ON A.num = B.num;Subqueries
- Notes中举得例子是,需要找到课程的学生人数大于所有课程的平均学生人数的课程。如果单纯进行AVG处理,那么想要获取的行将会被过滤掉了,这时候就需要用到子查询了。
1
2
3
4
5
6SELECT num
FROM enrollment
WHERE students >= (
SELECT AVG(students)
FROM enrollment;
)Set Operators
- ANY, ALL, UNION, INTERSECT, DIFFERENCE, IN.
Correlated Subqueries
- 子查询可以嵌套在WHERE中,也可以嵌套在FROM中。
Pattern matching
%可以匹配任何子串。_可以匹配任何单个字符。
Regular expression
- 使用前需要加~。
1
2
3SELECT artist_name, first_yr_active
FROM Artists
WHERE artist_name ~'^B.*';
Relation Algerbra
关系代数中返回结果不包含重复的tuple。
Projection($\pi$)
- $\pi_{name}(dog)$选择对应的列,类似于SELECT name FROM dogs;
- 在关系代数中不存在操作符等价于FROM。
Selection($\sigma$)
- 根据给定的条件过滤出具体的行。如: 对应关系代数的版本
1
SELECT name, age FROM dogs WHERE age = 12;
$\pi_{name, age}(\sigma_{age = 12}(dogs))$
或者$\sigma_{age = 12}(\pi_{name, age}(dogs))$ - Selection操作符同样支持
compound predicate,比如AND可以用$\wedge$来表示OR可以用$\vee$来表示, 如:对应的关系代数版本1
2
3SELECT name, age
FROM dogs
WHERE age = 12 AND name = 'Timmy';
$\sigma_{age=12 \wedge name=’Timmy’}(\pi_{name, age}(dogs))$
Union($\cup$)
- Compatible: 要求union的两个操作数必须拥同样数量的attribute, 并且对应的attribute必须拥有同样的类型。
Set Difference($-$)
- 和union一样要求Compatible
- 等价于SQL的EXCEPT语句, 比如$\pi_{name}(dogs) - \pi_{name}(cats)$只显示dogs表的行而不显示cats表的行。
Intersection($\cap$)
- 和union一样要求Compatible。
- 等价于SQL的INTERSECT语句。
CrossProduct($\times$)
- 就像在SQL中执行笛卡尔积,输出两个表中行的所有组合。 等价于$dogs \times parks$。
1
2SELECT ∗
FROM dogs, parks; - 不必要求属性数量一致。
Join($\Join$)
inner join: $dogs\Join_{dogs.name=cats.name}cats$,subscript中表示join的条件,也称作Theta join, “$\Join(\theta)$”。Natual join: $dogs\Join cats$,上面SQL中提到过,自然连接将会把两个表中所有同样的列自动合并。- 和selection操作符一样可以使用compound predicate。
- join都可以由cross和selection生成。
- $cats \Join_{\theta} dogs$和$\sigma_{\theta}(cats \times dogs)$是等价的。
- $cats \Join dogs$和$\sigma_{cats.col1=dogs.col1\wedge cats.col2=dogs.col2\wedge…\wedge cats.colN=dogs.colN}(cats \times dogs)$是等价的。
Rename($\rho$)
- 等价于SQL中的Alias。
- $cats\Join_{name=dname} \rho_{name->dname}(dogs)$,将dog中的name属性重命名为dname, 避免冲突。
Group By/ Aggregation($\gamma$)
- exp1 等价于$\gamma_{age, COUNT(*)>5}(dogs)$
1
2
3
4SELECT age
FROM dogs
GROUP BY age
HAVING COUNT(*) > 5; - exp2 等价于$\gamma_{age, SUM(weight), COUNT(*)>5(dogs)}$
1
2
3
4SELECT age, SUM(weight)
FROM dogs
GROUP BY age
HAVING COUNT(8) > 5;
SQL -> Relation Algebra
1 | SELECT teamid AS tid |
等价于
$$\rho_{teamid->tid}(\pi_{teamid}(\sigma_{position=’shootingGuard’}(players))-\pi_{players.teamid}(players\Join_{players.teamid=teams.teamid}teams))$$