15445Fall2022 P0&P1
DB也算是程序员的浪漫吧
一起通关吧!CMU15445fall2022 project0 and project1
Project0 C++ Primer
explicit关键字用于防止构造函数发生隐式转换noexcept关键字用于使函数不抛出异常- 左值和右值
- 能对表达式取地址的为左值,否则为右值
- 具名变量都为左值,右值不具名
- 右值又分为:expiring value(将亡值)和pure rvalue(纯右值)
- C++11中所有的值必属于左值、将亡值(C++11新增)、纯右值
- 引用
- 无论左值引用和右值引用都必须立即初始化,因为引用类型本身并不拥有所绑定对象的内存,只是该对象的一个别名
- 右值引用绑定一个右值引用类型变量就可以延长生命周期,利用这一特点可以做一些性能上的优化(如减少拷贝构造函数和析构函数的调用次数)
- 左值是指表达式结束后依然存在的持久对象;右值是指表达式结束时就不再存在的临时对象
- move constructor(移动构造函数), 移动堆中的资源,即不像拷贝构造函数一样复制现有对象的数据(在栈中),而是声明对象的指针指向临时对象的数据并清空临时对象的指针。可以防止在内存中不必要地复制数据(i.e.不必要地调用copy constructor)
- 深拷贝 vs. 浅拷贝(i.e. 拷贝构造函数 vs. 移动构造函数)
- std::move 并不会真正地移动对象,真正的移动操作是在移动构造函数、移动赋值函数等完成的,std::move 只是将参数转换为右值引用而已(相当于一个static_cast),配合使用移动构造函数
- 不能将一个unique_ptr直接赋值给另一个unique_ptr, 但可以用
std::move来进行赋值,或者通过函数返回 - std::move之后的右值, 表达式结束后就不再存在
- 继承关系,如果子类的构造函数没有显式地调用父类的构造函数,则默认调用父类的无参构造函数。
- std::unique_ptr的引用不能绑定到派生类的unique_ptr,若想创建派生类的unique_ptr可以用多态
- Trie的Remove需要用到辅助函数
- std::unqiue_ptr有三种初始化方式,构造函数,std::make_unique,std::move
Project1 Buffer Pool Management
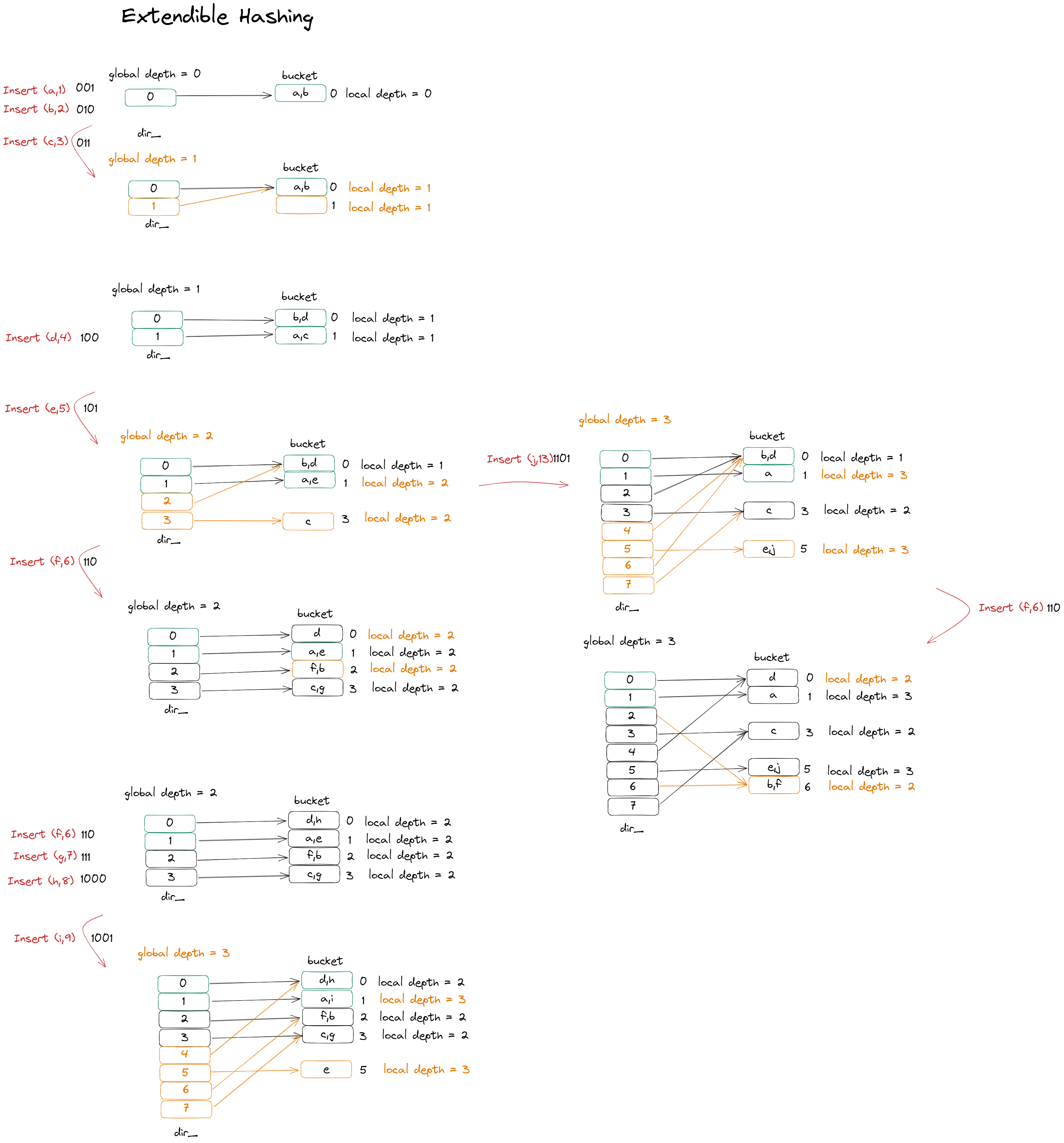
Extendible Hashing
- 直接向下这一部分状态图是project给的本地测试,向右侧这部分状态是自己想的测试
- override关键字有两个用途:
- 向读者表明这是个虚函数
- 编译器也知道这是个重载的方法,因此它可以检查你不是添加或者改变新的方法
- const_cast可以将non-const转换为const
- 桶在插入之前检测full再进行split
- 若global depth和local depth,具体见wiki
- 相等(即仅一个指针指向bucket),则对dir_进行扩容
- 不相等(即多个指针指向bucket),不需要对dir_进行扩容
- 如果桶满了要对桶进行split(通过增加global counter), 然后根据上面的情况选择是否double dir_的大小(通过resize function),reshuffle bucket, 创建一个新的bucket,在bucket发生split时,增加新增桶和当前桶的局部深度,再retry
- 只需要split当前full的bucket即可,将其映射到别的bucket, 注意bucket删除元素时,迭代器可能会失效(可以用一个del容器来收集要被删除的元素)
- local counter is bookkeeping
- extendible hashing可以将不同的哈希键映射到同一个桶里
- std::vector::resize()函数可以对额外增加的元素数目进行初始化
- remove函数可以在Bucket类中实现对每个bucket元素remove,再extendible hashing类中实现对哈希表元素的remove。
- mutable关键字可以删除const的限定
- std::scoped_lock提供了RAII机制(C++17特性)。
- 看了十一佬的博客后,几个关键的问题:
- dir 扩容时,新的指针应该指向哪里? A: split之后,扩容将增加一个bit。若除了增加的一位高位以外的bits都相等,则指向同一个bucket(称其为兄弟指针),根据其扩容前的global depth和相应的掩码操作。
- 如何重新安排指针? 只需要重新安排split bucket的兄弟指针即可,可以对原哈希索引和当前索引进行比较,若不相同则需要重新安排指针。每次split都需要重新安排指针,兄弟指针如何分配? dir_中与插入index后local depth位相等的即为兄弟指针,增加local depth之后以掩码的方式重新分配兄弟指针(可以将其分为两组,高位分别是0和1,一组指向原bucket,一组指向新的bucket)
- 在接口实现中获取数据成员时不要调用线程安全的接口,否则可能并发测试会特别慢
- 如果当前split bucket的local depth等于global depth,则不需要重新安排指针。
- 整个part的难点在split,可以分为以下几步
- 是否索引数组要扩容? 扩容伴随着全局深度的增加
- 新建bucket
- 重新安排指针
- 重新分配split bucket中的键值对
- IndexOf通过global depth生成的mask与std::hash返回的键值进行
&操作返回哈希目录的index,找到具体的bucket。 - 这里实现的可扩展哈希,存储的值是KV对
- 可扩展哈希的优势?
LRU-K
- LRU(LRU-1)为最近使用过1次,LRU-K为最近使用过K次
- 若少于K次访问的frame的distance被赋值为+Inf, 当frame的distance都是+Inf时,逐出frame中历史访问中时间戳最早(指的是当前frame的最早的访问记录)的那个(也就是经典的LRU算法)
- frame被evict或者remove之后它的access history、映射也要被移除,evictable属性也要设置为false,frame的evictable属性可以用一个bool数组来记录。
[[maybe_unused]]用于抑制未使用实体的警告(C++17特性)- std::advance可以增加迭代器的值
- 建议做这个part之前可以先去实现一下LC.146题
- LRU-1可以用哈希表(unordered_map)+双链表(list)来实现
- 双链表不支持随机访问, list::splice(具体STFM)可以将被访问或刚插入的元素移动到双链表头。
- list::splice可以将指定list中的迭代器指定的元素插入到this链表中的pos迭代器之前,就可以完成具体想要实现的功能, splice之后迭代器未失效(LRU-K的实现用不到这个方法)
- list中存储
- 哈希表中存储<frame_id, list的迭代器>,方便找到frame id在list中对应的位置
- 可以用list::assign()为list进行初始化
- 每进行一次RecordAccess就增加timestamp的值,记录frame id每次的访问时间。同时也要更新链表中该frame id所在的位置
- 注意: 增加一个辅助的二维数组对K个access history的个数进行标记,每个record[frame_id]中存储timestamp
- insert在当前迭代器之前插入元素
- 可以用std::prev和std::next来减少和递增迭代器, 注意std::next返回前进之后的迭代器,而std::advance不返回任何内容
- 记得保证所有操作都是线程安全的
- cpp读写锁(c++14特性)。共享锁和排他锁不能同时持有,可以同时多个线程持有多个共享锁,排他锁只能一个线程持有。括头文件
, 定义一个std::shared_mutex变量。共享锁上锁/解锁(lock_shared/unlock_shared),排他锁上锁/解锁(lock/unlock) - size_t(aka.long unsigned)需要8个字节的格式符,因此在printf的时候就不用4字节的%d而是%ld
- 如果当前frame的历史访问记录为0,那么再setEvictable()中即可直接返回(terminate)
- frame_id大于等于0,小于replacer的大小
- 如果是简单的LRU-1/LRU算法,用哈希表+双链表可以各操作保证O(1)的时间复杂度。若page引用大于等于K次即(LRU-K),既比较最近它们的第K次时间戳,直接遍历record数组(注意要筛去访问次数小于k的frame以及non-evictable的frame)找到具有最早时间戳的frame并驱逐即可; 若page引用小于K次(即LRU-1),则将这些page单独挑出来用LRU/LRU-1即可。这样可以得到最高的效率。
- 如果要remove一个访问记录大于等于k的frame,直接删除record数组中的记录即可
- LRU-K就是在LRU的基础上加了一些记录信息的容器而已。RecordAccess方法用来动态维护list;SetEvictable维护replacer的大小,设置evictable属性。
- 在维护LRU-1的链表时,如果元素重复访问,且访问记录次数小于k,不需要改变当前链表的状态,记录访问时间即可。
- 注意这里用的unordered_map而不是上一节实现的可扩展哈希
Buffer Pool Managerment Instance
- 了解过OS的虚拟内存机制之后,Buffer pool的大致实现应该能理解。
- 对atomic对象的访问可以建立线程间同步并按照std::memory_order的规定对非原子内存访问进行排序; std::atomic即不可复制也不可移动
- Page对象成员page_id跟踪具体的物理页面,如果Page对象没有包含物理页,那么page_id就被设为INVALID_PAGE_ID(-1);Page对象还包含了当前页的pin_count_(防止buffer pool evict这个页面)和is_dirty数据成员。p1之前实现的hashtable(page_id到frame_id的映射)和lru_k_replacer(跟踪要被evict的Page对象)将作为bufferpool的数据成员来实现
- 取frame先考虑freelist再考虑replacer
- 在DB中,又分为latch和lock。lock是高层次的原语,可以防止tuples,tables,databases受其他事务的影响。latch是低层次的原语(os中为lock),DBMS用于临界区,或者是数据结构(i.e.哈希表)的内部。
- page directory是page ids到数据库文件中page的位置的映射;page table是page ids到frame ids的映射
- page_id是从磁盘中调页的页号
- pages_即为缓冲池,存放磁盘页在主存中的缓存,free_list记录空闲帧的ID
- FetchNewPg如果所有frame都被pin住了就返回nullptr
- 用一个for循环遍历pages_数组来判断所有的frame是否正在使用,如果否则新建frame_id变量来记录free_list中或这是replacer中逐出的frame的id。
- SetEvictable(frame_id, false)就相当于pin操作,了解过LRU-K的实现后,pin住了的frame就不会被驱逐
- 如果page和frame之间没有产生映射,那么page id应该初始化为INVALID_PAGE_ID
- UnpinPgImp()中传入的is_dirty_参数只是告诉BPM刚刚对这个page进行读(FetchPg相当于进行读操作)还是写,unpin时不刷盘(这样也会降低性能),在fetch页面或者new页面时刷盘(lazy的机制),注意刷盘时传入FlushPgImg的page_id是刚被替换出去的frame的id,可以通过pages_[f_id].page_id,获取之前在frame上的page id(此时新映射的page id还未更新, 因此未覆盖)
- UnpinPgImp()传入的参数如果为is_dirty,并不是要直接赋给当前的page(如果原先是dirty,传入的参数是false,不可将当前的frame设置为non-dirty)
- ReadPage读page id在磁盘中存储的数据页
- Fetch时先考虑Flush如果当前替换得到的frame上有脏数据先写到磁盘上,再ReadPage从磁盘中读取Fetch目标page在磁盘上的数据到这个frame上。否则会覆盖
- 使用memset c库函数初始化页的data_区域,初始化为PAGE_SIZE个’\0’
- 切记刷盘之后要初始化当前frame的data数据为空
- Flush操作仅仅是将当前缓冲池中页的数据写回磁盘,然后将dirty flag置为false。
- 最后,结合文档中给的hint,加上自己的理解,注意细节,p1就完成啦